
June 08, 2020
In this blog post we’ll explore where ML developers run their app or project’s code, and how it differs based on how they are involved in machine learning/AI, what they’re using it for, as well as which algorithms and frameworks they’re using.
Machine learning (ML) powers an increasing number of applications and services which we use daily. For some organisations and data scientists, it is not just about generating business insights or training predictive models anymore. Indeed, the emphasis has shifted from pure model development to real-world production scenarios that are concerned with issues such as inference performance, scaling, load balancing, training time, reproducibility, and visibility. Those require computation power, which in the past has been a huge hindrance for machine learning developers.
A shift from running code on laptop & desktop computers to cloud computing solutions
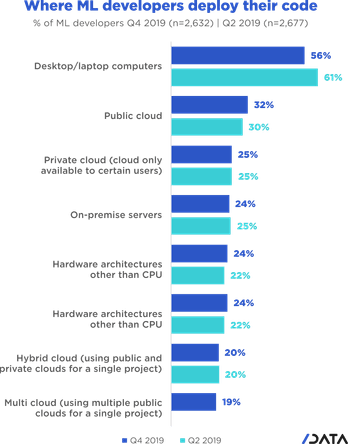
The share of ML developers who write their app or project’s code locally on laptop or desktop computers, has dropped from 61% to 56% between the mid and end of 2019. Although the five percentage points drop is significant, the majority of developers continue to run their code locally. Unsurprisingly, amateurs are more likely to do so than professional ML developers (65% vs 51%).
By contrast, in the same period, we observe a slight increase in the share of developers who deploy their code on public clouds or mainframe computers. In this survey wave, we introduced multi cloud as a new possible answer to the question: “Where does your app/project’s code run?” in order to identify developers who are using multiple public clouds for a single project.
As it turns out, 19% of ML developers use multi cloud solutions (see this multi-cloud cheat sheet here) to deploy their code. It is likely that, by introducing this new option, we underestimate the real increase in public cloud usage for running code; some respondents may have selected multi cloud in place of public cloud. That said, it has become increasingly easy and inexpensive to spin up a number of instances and run ML models on rented cloud infrastructures. In fact, most of the leading cloud hosting solutions provide free Jupyter notebook environments that require no setup and run entirely in the cloud. Google Colab, for example, comes reinstalled with most of the machine learning libraries and acts as a perfect place where you can plug and play to build machine learning solutions where dependency and compute is not an issue.
While amateurs are less likely to leverage cloud computing infrastructures than professional developers, they are as likely as professionals to run their code on hardware other than CPU. As we’ll see in more depth later, over a third of machine learning enthusiasts who train deep learning models on large datasets use hardware architectures such as GPU and TPU to run their resource intensive code.

Developers working with big data & deep learning frameworks are more likely to deploy their code on hybrid and multi clouds
Developers who do ML/AI research are more likely to run code locally on their computers (60%) than other ML developers (54%); mostly because they tend to work with smaller datasets. On the other hand, developers in charge of deploying models built by members of their team or developers who build machine learning frameworks are more likely to run code on cloud hosting solutions.
Teachers of ML/AI or data science topics are also more likely than average to use cloud solutions, more specifically hybrid or multi clouds. It should be noted that a high share of developers teaching ML/AI are also involved in a different way in data science and ML/AI. For example, 41% consume 3rd party APIs and 37% train & deploy ML algorithms in their apps or projects. They are not necessarily using hybrid and multi cloud architectures as part of their teaching activity.
The type of ML frameworks or libraries which ML developers use is another indicator of running code on cloud computing architectures. Developers who are currently using big data frameworks such as Hadoop, and particularly Apache Spark, are more likely to use public and hybrid clouds. Spark developers also make heavier use of private clouds to deploy their code (40% vs 31% of other ML developers) and on-premise servers (36% vs 30%).
Deep learning developers are more likely to run their code on cloud instances or on-premise servers than developers using other machine learning frameworks/libraries such as the popular Scikit-learn python library.
There is, however, a clear distinction between developers using Keras and TensorFlow – the popular and most accessible deep learning libraries for python – compared to those using Torch, DeepLearning4j or Caffe. The former are less likely to run their code on anything other than their laptop or desktop computers, while the latter are significantly more likely to make use of hybrid and multi clouds, on-premise servers and mainframes. These differences stem mostly from developers’ experience in machine learning development; for example, only 19% of TensorFlow users have over 3 years of experience as compared to 25% and 35% of Torch and DeepLearning4j developers respectively. Torch is definitely best suited to ML developers who care about efficiency, thanks to an easy and fast scripting language, LuaJIT, and an underlying C/CUDA implementation.
Hardware architectures are used more heavily by ML developers working with speech recognition, network security, robot locomotion and bioengineering. Those developers are also more likely to use advanced algorithms such as Generative Adversarial Networks and work on large datasets, hence the need for additional computer power. Similarly, developers who are currently using C++ machine learning libraries make heavier use of hardware architectures other than CPU (38% vs 31% of other developers) and mainframes, presumably because they too care about performance.
Finally, there is a clear correlation between where ML developers’ code runs and which stage(s) of the machine learning/data science workflow they are involved in. ML developers involved in data ingestion are more likely to run their code on private clouds and on-premise servers, while those involved in model deployment make heavier use of public clouds to deploy their machine learning solutions. 31% of developers involved across all stages of the machine learning workflow – end to end – run code on self hosted solutions, as compared to 26% of developers who are not. They are also more likely to run their code on public and hybrid clouds.
By contrast, developers involved in data visualisation or data exploration tend to run their code in local environments (62% and 60% respectively), even more so than ML developers involved in other stages of the data science workflow (54%).
Developer Economics 18th edition reached 17,000+ respondents from 159 countries around the world. As such, the Developer Economics series continues to be the most global independent research on mobile, desktop, industrial IoT, consumer electronics, 3rd party ecosystems, cloud, web, game, AR/VR and machine learning developers and data scientists combined ever conducted. You can read the full free report here.
If you are a Machine Learning programmer or Data Scientist, join our community and voice your opinion in our current survey to shape the next State of the Developer nation report.




Contact us
Swan Buildings (1st floor)20 Swan StreetManchester, M4 5JW+441612400603community@developernation.net



